If you are interested in serverless architecture then you probably have read many contradictory articles and might wonder, whether serverless architectures are cost effective or expensive. I would like to clear the air around effectiveness of serverless architectures through an analysis of a web scraping solution. The use case is fairly simple – at certain times during the day, let’s say every hour from 6am to 11pm, I want to run a Python script and scrape a website. The execution of the script takes less than 15 minutes. This is an important consideration to which we will come back later. The project can be considered as an ETL process without a user interface and can be packed into a self-containing function or a library.
Subsequently, we need an environment to execute the script, thus we have at least two options to consider: on-prem, e.g. your local machine, a Raspberry Pi server at home, a virtual machine in a data center, etc.; or deploy it in the cloud. At first glance, the former option might feel more appealing – you have the infrastructure available free of charge, why not to use it? The main concern of an on-prem hosted solution is the reliability – can you assure its availability in case of a power cut, a hardware or network failure? Additionally, does your local infrastructure support continuous integration and continuous deployment (CI/CD) tools to eliminate any manual intervention? E.g. automatic deployment to a production environment when you update your script. With these two constraints in mind, I will continue the analysis of the solutions in the cloud rather than on-prem.
Let’s start with the pricing of three cloud-based scenarios and go into details below.
| 10 min per hour of execution time | 30 min per hour of execution time | |
|---|---|---|
| EC2 – t3.nano, 512MB ($0.0052 per hour), 24x7 | $3.74 | $3.74 |
| ECS Fargate – EC2 Spot instance, 0.25 vCPU, 512MB | $0.34 | $1.03 |
| Lambda – 512MB | Monthly free tier | Monthly free tier, 2 runs capped to 15 min * |
*The AWS Lambda free usage tier includes 1M free requests per month and 400,000 GB-seconds of compute time per month. AWS Lambda pricing
The first option, an instance of a virtual machine in AWS so called EC2, is the most primitive one. It definitely does not resemble any serverless architecture, however let’s consider it as a reference point or a baseline. This option is similar to an on-prem solution giving you full control of the instance, but you would need to manually spin an instance, install your environment, set up a scheduler to execute your script at a specific time and keep it on for 24x7. And don’t forget the security – set-up a VPC, route tables and etc. Additionally, you will need to monitor the health of the instance and maybe, run manual updates. Doesn’t sound like a fun, right?
The second option is to containerize the solution and deploy it on Amazon Elastic Container service (ECS). The biggest advantage of this option is platform independence – having a Docker file with a copy of your environment and the script enables you to reuse the solution locally, on AWS platform or somewhere else. Now, a huge advantage running it on AWS is that you can integrate with other services, e.g. CodeCommit, CodeBuild, AWS Batch, etc. or benefit from discounted compute resources such as EC2 Spot instances.
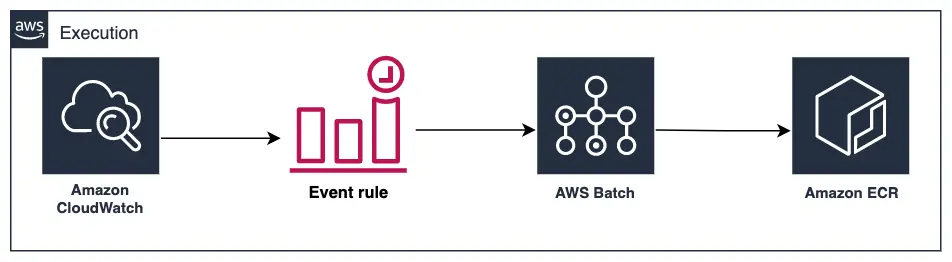
The architecture, seen in the diagram above, consists of Amazon CloudWatch, AWS Batch and Amazon Elastic Container Registry (ECR). CloudWatch allows you to create a trigger, e.g. start a job when a code update is committed to a code repository; or a scheduled event, e.g. execute a script every hour. As per the description above, we want the latter, i.e. execute a job based on a schedule. When triggered, AWS Batch will fetch a pre-built Docker image from Amazon ECR and execute it in a predefined environment. AWS Batch is free of charge service and allows you to configure the environment and resources needed for a task execution. It relies on Amazon Elastic Container service (ECS) which manages resources at the execution time. You only pay for the compute resources consumed during the execution of a task.
Now, you might wonder where a pre-built Docker image came from. It was pulled from Amazon ECR and you have two options to store your Docker image there. You can build a Docker image locally and upload it to Amazon ECR, or you just commit few configuration files, namely Dockerfile, buildspec.yml and etc., to AWS CodeCommit (code repository) and build the Docker image on AWS platform. The latter, outlined below, allows you to build a full CI/CD pipeline. E.g. after updating a script file locally and committing the changes to a code repository on AWS CodeCommit, a CloudWatch event is triggered and AWS CodeBuild builds a new Docker image and commits it to Amazon ECR. When a scheduler starts a new task, it fetches the new image with your updated script file. If you feel like exploring further or you want actually implement this approach please take a look at the example of the project.

The third option is based on AWS Lambda service which allows you to build a very lean infrastructure on demand, can scale continuous and has very generous monthly free tier. The major constrain of Lambda service is that the execution time is capped to 15 minutes. Now, if you have a task running longer than 15 min then you need to split it into sub-tasks and run them in parallel, or fallback to option two. By default, Lambda gives you access to standard libraries, e.g. the Python Standard Library and in addition to that, you can build your own package to support the execution of your function or use Lambda Layers to have access to external libraries or even external Linux based programs.

You can access AWS Lambda service via the web console and create a new function, update your Lambda code or execute it. However, if you go beyond “Hello World” functionality, you might realize, that online development is not sustainable. E.g. if you want to access external libraries from your function, you need to archive them locally, upload to S3 and link it to your Lambda function. One way to automate Lambda function development is to use AWS Cloud Development Kit (AWS CDK) which is an open source software development framework to model and provision your cloud application resources using familiar programming languages. Initially, the setup and learning might feel strenuous, however the benefits are worth of it. To give you an example, please take a look at a Python class below, which creates a Lambda function, CloudWatch event, IAM policies and Lambda layer.
from aws_cdk import (
aws_events as events,
aws_lambda as lambdas,
aws_events_targets as targets,
aws_iam as iam,
core
)
from aws_cdk.aws_lambda import LayerVersion, AssetCode
class LambdaAppStack(core.Stack):
def __init__(self, scope: core.Construct, id: str, **kwargs) -> None:
super().__init__(scope, id, **kwargs)
with open("index.py", encoding="utf8") as fp:
handler_code = fp.read()
role = iam.Role(
self, 'mylambdaRole',
assumed_by= iam.ServicePrincipal('lambda.amazonaws.com'))
role.add_to_policy(iam.PolicyStatement(
effect = iam.Effect.ALLOW,
resources = ["*"],
actions= ['events:*']))
….
lambdaFn = lambdas.Function(
self, "Singleton",
code=lambdas.InlineCode(handler_code),
handler="index.lambda_handler",
timeout=core.Duration.seconds(600),
runtime=lambdas.Runtime.PYTHON_3_6,
memory_size=512,
role = role
)
rule = events.Rule(
self, "Rule",
schedule=events.Schedule.cron(
minute='59',
hour='6-20/4',
month='*',
week_day='*',
year='*'),
)
rule.add_target(targets.LambdaFunction(lambdaFn))
ac = AssetCode("./python")
layer = LayerVersion(self, "mylambda1", code=ac,
description="athome layer",
compatible_runtimes=[lambdas.Runtime.PYTHON_3_6],
layer_version_name=mylambda-layer')
lambdaFn.add_layers(layer)
As you can see, you can have infrastructure as code in Python language and all changes will be stored in a code repository. For a deployment, AWS CDK builds an AWS CloudFormation template, which is a standard way to model infrastructure on AWS. Additionally, AWS Serverless Application Model(SAM) allows to test and debug your serverless code locally, therefore you can indeed create a continuous integration.
An example of a Lambda based web scraper can be found on github.com.
In this blog post, we have reviewed two serverless architectures for a web scraper on AWS cloud. Additionally, we have explored the ways to implement a CI/CD pipeline in order to avoid any future manual interventions. If you have any question, feel free to contact me on Twitter @dzidorius.