In this article, I will outline my mental model for running a science project. Specifically, I’m referring to data or applied science projects, drawing from my experience of over 9 years at AWS and Amazon. You might argue that in agile environments like startups or smaller companies, the approach could differ, but aside from an additional layer of hierarchy, I don’t anticipate significant deviations.
The most crucial question to ask at the start of a project is whether the business problem is well-defined. A well-defined problem could be something like: what is the impact of a sales promotion? Or, what is the value of adding a new feature? However, as a scientist, you’re more likely to encounter vague business problems — if any are presented at all. For instance, you might be introduced to a business organisation and asked to figure out how you can make an impact on profitability.
Early in my career at AWS, I was introduced to a sales leader who wanted help with data science. We had a few meetings where I tried to identify the business problems they aimed to solve. To my surprise, they didn’t have any clear issues in mind and simply hoped I would work some “magic.” In hindsight, I should have proposed concrete projects focused on improving profitability, rather than an optimization project. It took me a few years to realize that a rapidly growing sales organization is primarily concerned with increasing profit by selling more, not through optimization efforts like churn analysis.
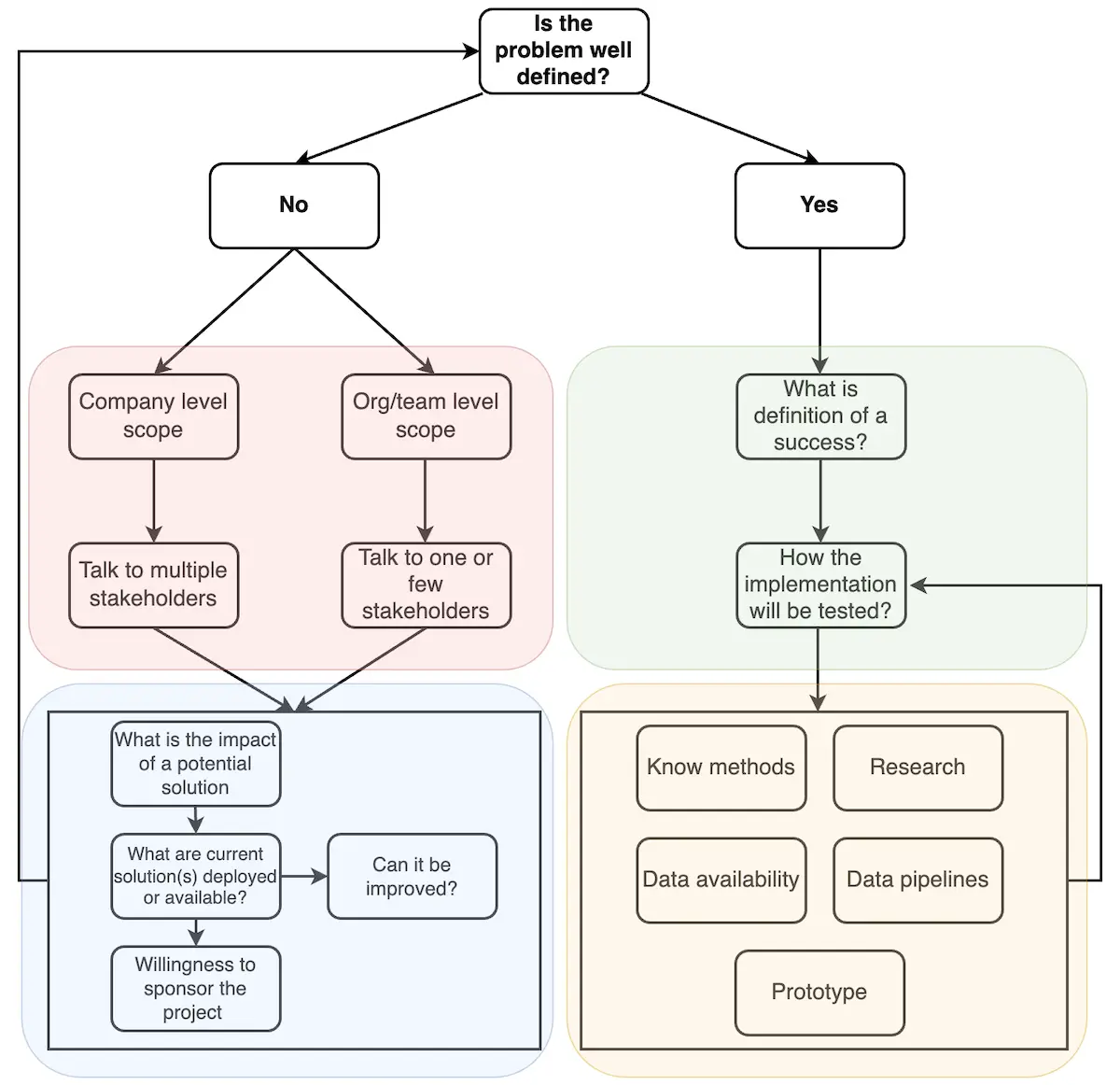
To avoid similar challenges, I developed the chart below, which outlines four key areas involved in running a science project. The red section represents the stakeholders and sponsors, the blue section covers scoping, the green defines the metrics and the definition of success, and the yellow focuses on what’s needed to implement and execute the project. Some might argue that only the right side of the diagram, particularly the yellow box, defines a science project, but in my experience, that’s usually the “easy” part.
Stakeholders
It’s quite rare for business leaders to present a clear business problem or a well-defined question. In large organizations like Amazon, the left side, comprising the red and blue squares, tends to be where senior or principal roles are deployed, as many problems are vague or poorly defined. You might argue that handling stakeholders and scoping projects are responsibilities typically assigned to managers or product managers. However, in my experience, individual contributors in tech roles are often heavily involved or expected to take the lead, particularly in FAANG - type companies.
When identifying stakeholders, I usually start from the ground up—finding a team that needs a solution, building a plan, and scaling from there. The top-down approach may target higher impact but often has a much higher failure rate due to added layers of hierarchy and tends to result in multi-year projects.
Scoping a project
Once stakeholders are identified, the next step is to assess the potential impact of the project. You want to avoid working on projects with a lower ROI than the value you bring. Additionally, this helps you prioritize projects if you’re choosing between several. One critical question during scoping is whether there are already deployed solutions or ones that can be acquired. This can be tricky, as you might receive biased responses claiming no solution exists or that it’s inadequate. A shiny new project is always more appealing to those involved, but repurposing or improving an existing solution can lead to significant cost savings and knowledge transfer.
When it comes to project sponsorship, the discussion can quickly turn sour. However, for a project to continue successfully, you need to ensure that your stakeholders, or “customers,” are truly willing to invest. Don’t assume that the only cost is your time—it’s a multi-layered issue. Can you access the necessary data, or do you need support from a partner team? What does the testing phase entail, and do you have the resources allocated for it? If the project succeeds, what will the continuation look like? Do you have the means to take it to production and maintain it? In my experience, the latter is often overlooked until it becomes a significant problem.
One of the common pitfalls in data science projects is aligning on the results. By this, I mean that stakeholders are eager to use the project’s output to validate their assumptions—if the results align with their needs. However, when the results conflict with their expectations, the adoption of those findings can be quickly “killed.” For example, we once developed a methodology to assess the impact of specific business actions. The quantitative approach revealed that not every action aligned with qualitative measurements, which are often prone to misinterpretation. As a result, we faced significant resistance when attempting to scale the project across the organization.
Metrics and definition of success
At this stage, your project is well-defined and outlined on a paper. You can begin assembling a team to execute it, but before diving in, you need to define what the success will look like. By that I mean, that you need to look in the future and estimate how a good outcome looks like. E.g. you might decide that your model will be 10% above a baseline or your new method will be able to estimate a causal effect of a specific action. The clear definition is like the North Star which will lead you to the goal.
Next, the metrics and a plan for the experimentation phase. This means establishing a baseline for your model and planning how the experimentation will be conducted. You should determine the methods you’ll use to test your model (e.g., A/B testing for online models) and set clear expectations for the impact you hope to achieve. It’s crucial that your stakeholders are heavily involved at this point, and they must commit resources to support the process. In most cases, this means getting their agreement on the exact steps that will be taken.
For example, I once built a highly promising model, but testing its performance required the involvement of multiple people. Initially, everyone was motivated to follow the AI-enabled recommendations, but after some time, they reverted to their usual routines. It took significant resources to get the project back on track. In hindsight, I should have had clear metrics in place and handed over the responsibility for test implementation to the business unit manager.
Execution
As I mentioned earlier, this part of the project is the easiest in terms of delivery. While you may encounter difficult scientific problems to solve, the three pillars discussed previously (stakeholders, scoping, and experimentation) provide a stable foundation for successful execution.
I purposely left the boxes in the lower right square unconnected because execution can happen either sequentially or in parallel. You might want to ensure the project has solid scientific grounds before progressing, or you might prioritize checking data availability and quality upfront. Flexibility here allows you to adapt the execution based on the nature of the project.
For tracking the project’s progress, weekly or biweekly check-ins work well, especially when the milestones are clear. Usually, the first iteration results in a quick prototype, which helps to realign with stakeholders before diving deeper into the work. This way, you stay on track with the project’s goals and can adjust as needed without wasting time or resources.
To wrap things up, I realize my mental model for running science projects is shaped by my own experiences, and it might not apply to every situation. I’m open to hearing different perspectives and learning about other approaches. If you have ideas or suggestions you’d like to share, feel free to reach out to me at blog@dzidas.com.