Peer to peer lending allows to lend money to unrelated individuals without going through traditional financial service such as bank, credit union, etc. Nevertheless, there is an intermediary - service and platform provider. The provider verifies the identity of the borrower and income status, processes the payments, promotes its platform, deals with bad loans or demands bankruptcy for the borrower.
The advantage of peer to peer lending for the borrowers is lower interest rate and higher rate for lenders. However, higher rate comes with higher risk - the return is more volatile than a bank deposit.
Regardless of many lending platforms such us Prosper.com (US), zopa.co.uk (UK), www.fundingcircle.com (UK), auxmoney.com (DE), pret-dunion.fr (FR), comunitae.com (ES), lendico.com (global), majority of platforms accept only the investment from local investors. However bondora.com (EE) allows invest into three markets - Estonia, Finland and Spain and accepts investors from across Europe. Additionally, the rate of return at bondora.com is not fixed as in other platforms and allows much higher returns. However, there is a possibility that you may lose some or all of your initial investment as it is not protected by any financial compensation scheme.
The company behind bondora.com is isePankur AS, which is based in Estonia, a small country in north of Europe. The really amazing thing about bondora.com, that they share data with everyone. The data-set gives us an opportunity to glimpse at the performance of the company and a possibility to build our own credit scoring model!
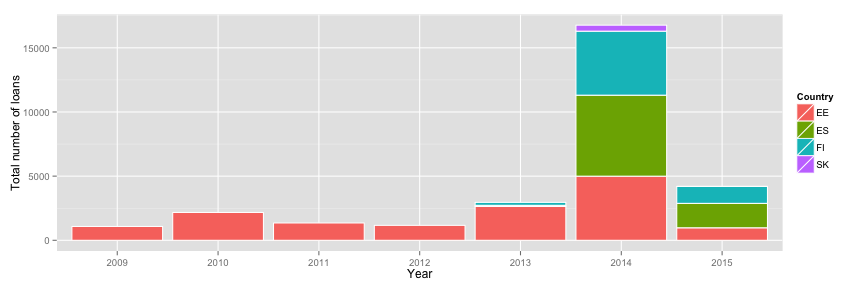
The data goes back to 2009 and the chart below shows the total number of loans and funded loans per month. It looks like the business exploded in 2013 and the following charts will give us a few clues. In 2013 bondora.com became more active in Finland and Spain markets, though it was in 2014, when the grow skyrocketed in these markets.
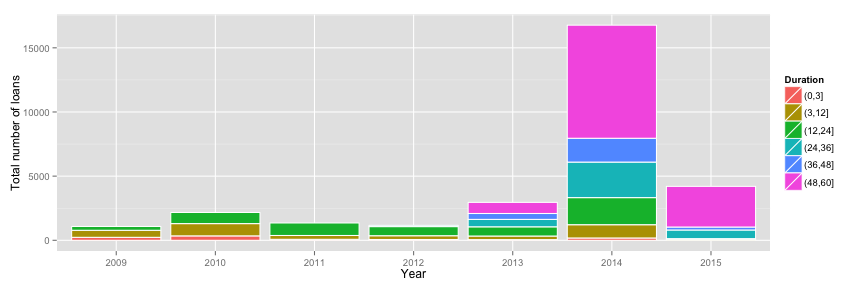
Another big change, which might ignited the grow of bondora.com is the shift in the duration of the loans. Dominant loan duration before 2013 was 1-2 years, but in 2013 the company started issuing 5 years loans, which became the primary duration in 2014 and was half of all loans.
The latest data-set has data about 29688 loans and 172 columns or features (depending which parlance you prefer). Below you can see a partial print screen of the interface and dozen of the features.
###Model building###
Now, that we are familiar with bondora’s data-set, let’s move to model building. The prediction model can predict two types of outcomes - categorical (yes/no, true/false classes) or numerical (one is less than one hundred). Although most credit scoring models are built to return a credit score for a borrower, I have opted for simple model, where the outcome has two classes: good or bad.
The definition of “good” class is straight forward - the class in which you are willing to invest or give a credit, but “bad” class definition is complicated. The data-set has data about the borrowers who were late with their payments for 7, 14, 21, 60 days and defaulted loans. How bad is a borrower if he is late for X days? True, he doesn’t respect the schedule and the contract for various reason such as harsh life, distraction or any other reason. However, once he is back on track he pays what he owns, plus late charges, which leads to higher return for additional risk.
The defaulted loans really sounds as bad loans, right? Well, what if the loan defaults, but you get back the principal and partial interest rate? Doesn’t sound that bad, does it? What you really don’t like is the default on the loan and zero payments - these loans are the fraud and you want to avoid them. So let’s mark them as a “bad” ones.
Beside choosing the outcome, it took me awhile to realize another problem with the data-set - the shift in the business model. Nowadays, most of the loans are issued for 5 years and the data-set doesn’t event have data on matured 5 years loans! So I did the trick - I marked all 5 years loans as repaid which are still “alive” after 2-3 years.
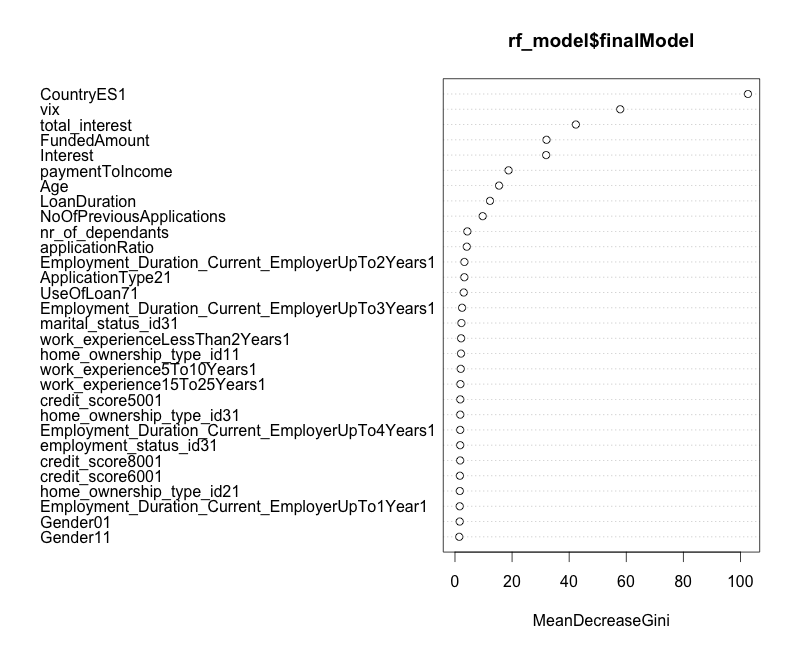
While working on a few machine learning projects I quickly learned, that the biggest impact on performance of the model comes not from the fancy machine learning algorithms, but from well engineered features. In the chart below you can find, that 3rd feature is “total_interest”, which is made of “Interest” and “LoanDuration”. The two features perform well, but the derived feature has much bigger weight.
Additionally, I have added data about VIX index. The index tracks volatility of the stock market via S&P500 index - its value increases during the crisis and falls back during calm times. By adding independent source the performance of the model increased 2%.
After initial cleaning of the data-set and feature engineering it was time to build a simple model. My favorite machine learning algorithm is Random Forest for the following reasons: you can feed almost any raw data and it chew happily; the algorithm itself is easy to understand, nevertheless it is kind of black-box; it gives the weights of the features:
###Model metrics###
In classification task precision and recall are used frequently for model metrics. The predicted value can be assigned to four classes: True Positive - real fraud (model predicted True and value was True), True Negative - not a fraud (model predicted False value and value was False), False Positive - not fraud marked as a fraud (model predicted True, however value was False) and False Negative - real fraud marked as not fraud (model predicted False, but the value was True).
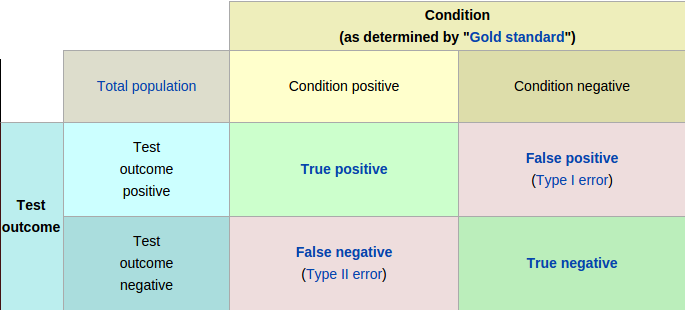
In case of p2p lending, if you commit False Positive error (Type I), you just miss one investment. You main concern is False Negative (Type II) errors, because you will be loosing money on the bad investment. Positive predictive value metrics is used for performance evaluation: sum(True positive)/sum(Test outcome positive)
###Blending###
Funny, but the blending works well with ML algorithms and with the people. Michael Nielsen in his book “Reinventing Discovery: The New Era of Networked Science” gives many examples how the collective intelligence can be more powerful than single mind. The idea is very simple - if you gather predictions from dozen of people or ML models then the average score will better than the best single prediction. There is one pitfall - if the predictions are given by “herd mind” then the result most likely be horrible. So, in ML environment try to include very different algorithms - decision trees, linear models, neural networks, etc. to sustain diversity.
For my final model I blend tree algorithms - Random forest, SVM and generalized boosted modeling (GBM). If all of them predict, that the loan is not a fraud, then I will make an investment.
###Real time data###
The modeling part is done, but without real time data it is just waste of time. Fortunately, there is a nice Python framework for web crawling - Scrapy. Initial time investment in the tool might look significant, but because it is robust it won’t be your concern any time soon, unless the platform gets face-lift…
###Automated investment###
Selenium is a suite of tools to automate web browsers across many platforms. It is widely used for web interface testing purpose, however any web-based task can be automated.
Once I have real time data I feed my model with it to find out which loans are good for the investment. Acquired list is send to Selenium script, which logins into the platform and makes the investments.
###Infrastructure###
My first idea was to use Raspberry Pi for the project, however I had the problems setting up R-language and Python frameworks. So, I rented an instance on DigitalOcean for 10 dollars a month (there is 5$/month option as well) and it worked well. Meanwhile, I realized, that I don’t need the server for 24 hours a day.
The solution was to power-on four times a day and shutdown the server once the job is finished. But as you probably know, powering-off your server is not enough to save you from paying - you need to archive your virtual instance (the same applies to Amazon AWS). So, I came up with the script, which creates a virtual image from the archive, powers it on, runs the crawler, runs R mining module, makes the investments if necessary and then shutdowns the instance, archives the image and deletes virtual machine.
Does it sounds good? Well, it was good, until I went on holiday for one week without almost any access to Internet. At the end of my vacation, I found, that every day four new servers were created and were still spinning… Turns out, that Raspberry Pi was able to initiate new instances, but wasn’t able to shutdown and delete. The support at DigitalOcean have asked for the log files from my server and I ended up paying the bill, because it was almost non-existant on my RaspPi. The lesson taken - log as much as possible and incorporate health checks for virtual machine in your scripts.
###Results###
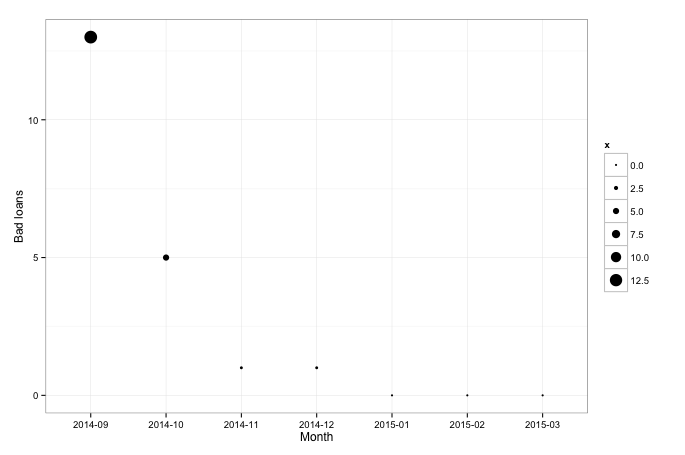
I started my investments at Bondora in September 2014. At the beginning all my investments were done via Bondora’s investment engine, where you can define investment parameters (country, risk profile, etc.). Somewhere in November - December I decided, that I will rely on my own engine only. Below you can see, that the engine based on machine learning algorithms does good job by avoiding bad borrowers.