Lack of operational excellence threatens us, not AI
Can we talk about AI without talking about AI? Here we go. While traversing Germany, I booked a hotel for the night which fitted my needs: outside a city and, most importantly, self-check-in, as I was planning to stop at midnight, have a rest, and continue. Of course, there was a surprise. At 12:30 a.m., when I was trying to unlock the room with the keyless system, the lock wouldn’t budge. I checked with another guest that my approach was right; the lock was just not reacting. In such a situation, the fallback is to call a support number, wait on the line for 20 minutes, and get the issue resolved. The catch? The support line’s working hours are from 9 a.m. to 6 p.m. And if you have a problem, that’s your choice!
The power of prototyping
Why would a company or person be interested in creating a prototype? The answer is simple - to test a new idea, improve a product, or find a better or more optimal way to solve a business problem. According to Statista, 56% of organizations worldwide expect generative AI to enhance these aspects, though many likely don’t have an exact plan for implementation. In this blog post I want to share my experience on building prototypes, quickly testing ideas and most importantly, innovating.
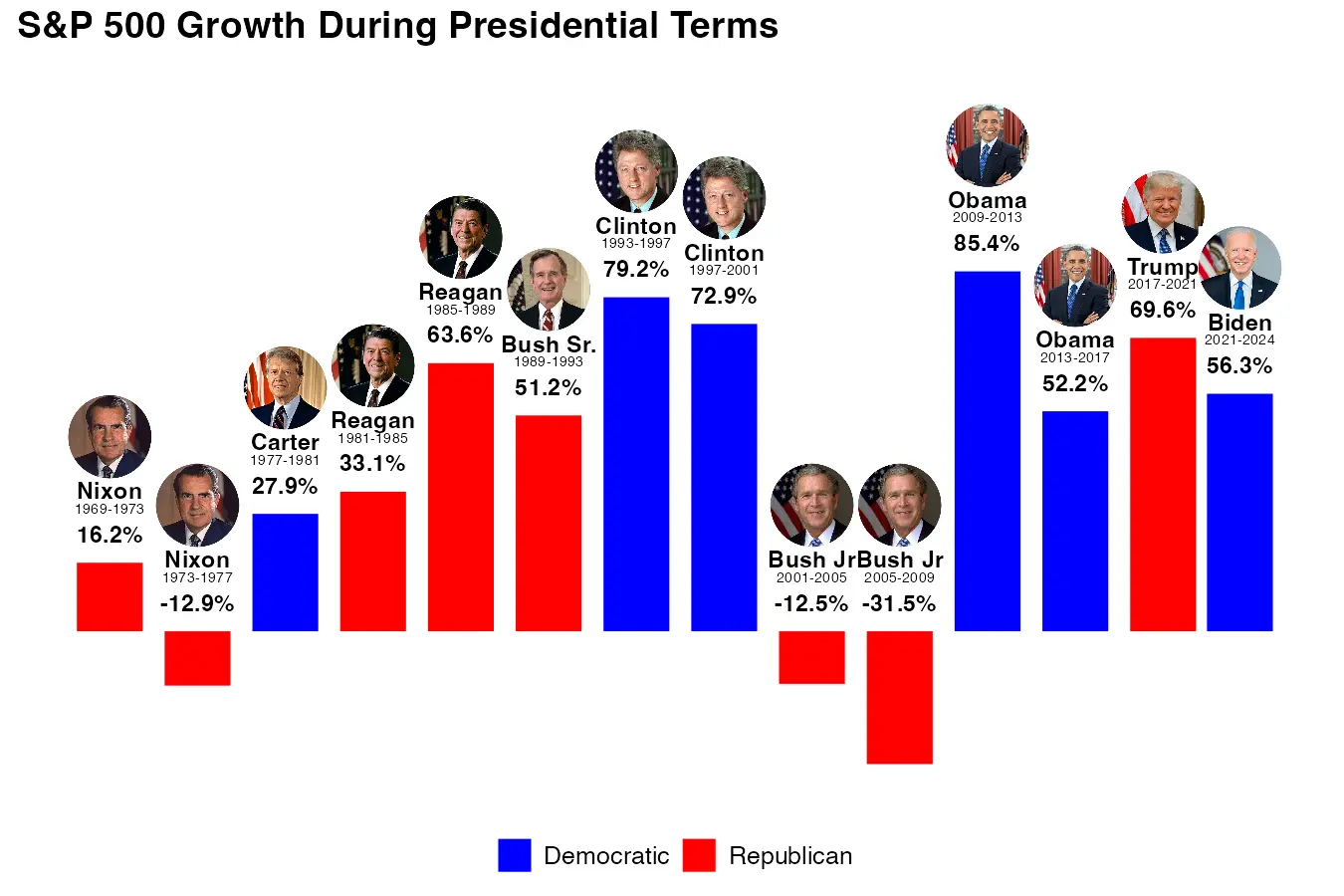
Expected returns under a Republican president
How to run data science projects
In this article, I will outline my mental model for running a science project. Specifically, I’m referring to data or applied science projects, drawing from my experience of over 9 years at AWS and Amazon. You might argue that in agile environments like startups or smaller companies, the approach could differ, but aside from an additional layer of hierarchy, I don’t anticipate significant deviations.
Why are sellers leaving profit on the table?

How does a 1% increase in traffic cost your health?

I got hit by HackerNews - a luck or a skill?
Causal inference as a blind spot of data scientists
Throughout much of the 20th century, frequentist statistics dominated the field of statistics and scientific research. Frequentist statistics primarily focus on the analysis of data in terms of probabilities and observed frequencies. Causal inference, on the other hand, involves making inferences about cause-and-effect relationships, which often goes beyond the scope of traditional frequentist statistical methods.
Challenges and ideas for charging an EV in Europe
 A view from a Tesla charging station in Germany
A view from a Tesla charging station in Germany
Navigating the Future of AI: Strategies for Survival
Lately, reading the news and following updates about advancements in AI, specifically in Generative AI and chatGPT, gave me mixed feelings - on one hand, we are on something big and impactful, but at the same time it feels like a potential threat to the future. And I’m not alone - NLP students lost their field of research overnight, meanwhile some orgs at FAANG became obsolete. It is an old news that chatGPT can pass a software developer tests at FAANG, an exam to become a lawyer or generate inspirational phrases for your YouTube shorts. But I’m sceptical that we will experience a radical transformation in a short time of a few years, but rather, it will be an iterative change which can take a decade or more. But as a story goes, a slowly boiled frog was too comfortable to jump out of a pot, the fate we shall avoid.